Knowledge Writing In Context (KWIC)
Organisations are increasingly concerned with knowledge management [Shadbolt 1999] and have amassed large intranets (multimedia information Web sites) in order to capture their corporate knowledge [Heath 2000]. This resource-base has typically been gradually amassed in an unsystematic fashion; consequently metadata, indexes or glossaries are usually based on inconsistent and unmanaged vocabularies. Furthermore, the ways in which this information is put to use after publication varies with the role of each user within the organisation and the type and context of the information that has been assembled. As the intranet grows in size and complexity, it becomes impractical to build and use it in the present ad hoc and labour intensive fashion. The Semantic Web [Berners-Lee 2001] is more than just a repository of information; the meaning of the documents, knowledge about their authors and the reasons for their publication are all used to infer contextually appropriate associations, i.e. knowledge. The ability to publish new material so that at some later date it can be appropriately reused should be the goal of the IT strategy of any organisation with a suitably sophisticated infrastructure.
By way of example, a manager writing a policy statement is required to draw together information held in a number of business documents: corporate vision statements, corporate strategy documents, departmental policy documents, management summaries, financial reports, public relations statements etc. While reading the content of those documents, the manager will also want to know their purpose (e.g. the intended audience) and authorship (e.g. the authorsÆ position of influence) in order to be confident about any inferences made from the documents. However, managers do not often have sufficient time to digest the supplementary documentation in order to evaluate its appropriateness. What they require is a system that will offer relevant material from appropriate documents, based on the context in which new material is being written. The new document should be published in a form that facilitates reuse of the new knowledge embodied within it, and which provides explicit references to the sources of any reused knowledge.
There exist established and effective means of modelling relationships within a structured hypermedia information space [Fountain et al. 1990]. Hypermedia design methodologies [Lowe & Hall 1999] address the relations between information assets to provide site design and navigation features at the macro-structure (document or Web page) level. We believe that by extending these design methodologies to represent the relationships at a microstructure level, the hypermedia design structure can be adapted to encode knowledge relationships, and hence form the basis of the knowledge services described above.
Program and Methodology.
There exist a number of recognized hypermedia design models and methodologies: Hypermedia Design Model (HDM) [Garzotto et al. 1993], the Relational Management Methodology for Hypermdia Design (RMM) [Isakowitz et al., 1995], Object-Oriented Hypermedia Design Model (OOHDM) [Schwabe et al., 1995], Web Modeling Language (WebML) [Ceri et al. 2000]. Each has its own advantages and disadvantages [Christodoulou et al. 1998].but all of the design models focus on imposing a macro-structure on the collection (by clustering, partitioning and decomposing themes). Beyond that, we require a model that will also expose the existing relationships within the microstructures of the individual documents, e.g. that bullet point 1 of a Company policy document is expanded in paragraph two of the Departmental policy document. These parallel requirements can be satisfied by an interleaved model (Figure 1).
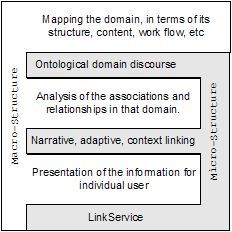
Figure 1 Interleaved Models
The existing models (white areas) examine the macro-structure of the collection (web site, intranet, repository etc.) that is used to design navigation and presentation strategies for the documents, and provide a æcatalogue of assetsÆ. The layers shown are independent of the exact design method used, and may work with either an object-orientated or entity-relational approach. The traditional weakness of these existing layered design models is the lack of æcementÆ connecting the layers [Lowe & Hall 1999], i.e. in practice the result of one activity does not feed into the next. The proposed microstructure (greyed area) not only fulfils the knowledge modelling requirements above, but also provides the missing æcementÆ by considering the knowledge contents of the documents. We propose to exploit the knowledge modelling work of the Knowledge Management and Semantic Web communities by applying ontologies to describe the interrelationships between concepts embedded in the documents, and exposing these concepts whilst the document is being written. The availability of the microstructure will support authors with appropriate knowledge for constructing texts (i.e. narrative and rhetorical material) and support readers with adaptive and context-sensitive linking techniques.
Objectives and research issues
The aim of this project is to produce a novel writing tool, which is underpinned by an enhanced knowledge structure and hypermedia design model. As a result we aim to help authors improve the coherence and consistency of the documents they are creating by helping to assimilate key knowledge in each new document. Our objectives are:
- To investigate how to support the writing by modelling, realizing and tracking the intrinsic knowledge held in documents.
- To investigate the requirements of a knowledge structure and hypermedia design model that will embrace the micro- and macro-structures of a document collection.
- To implement a demonstrator, based on real world scenarios, to investigate the use of such technology and its wider implication on the authoring processes.
The research issues that will be addressed by the project include:
- The representation of knowledge that would otherwise be lost inside the content of a document: for example in the business context: issues, action items, policy statements, management decisions etc.
- The issues and processes involved in reusing the identified knowledge structure.
- The representation and inter-operation of the macro- and micro- information structures of a corporate intranet.
- The mechanisms required to support locating and reusing knowledge structures as part of the writing process.
- The development of suitable interfaces to present the resulting knowledge structures to the user, to ensure that they are appropriate.
Programme of work.
The fulfilment of the outlined objectives will entail the following tasks:
- Requirements Gathering. Scenarios will be used to ground the requirements within the real world setting, independently of current technological limitations. These scenarios will first be used to identify the key issues in the construction and reuse of documents. They will also be used to identify the weakness of any current methodologies for both the macro- and micro- level information structures and ultimately to validate any resulting hypermedia design methodologies.
- Knowledge Structures and
Hypermedia Design.
Using the outputs of task 1, determine the infrastructure,
technologies and processes required in the design and creation of documents
within an intranet. The main focus of the activity will be in constructing a
useful and usable model for integrating knowledge structures and hypermedia
design (see figure 1). By the use of appropriate data structures, web standards
and services the realisation of the model will result in the development of
writing tools which will support the following parts of the knowledge
lifecycle:
- Writing in context Investigate the issues and model the processes by which users can create material that includes key business information from other corporate documents.
- Reuse the content of document. Investigate the methods required to capture and expose the key information in a document created by this process to facilitate reuse.
- Integration. To support the deployment of the writing tools, we will investigate the use of existing ontological, contextual hypermedia tools. (Since documents are generally produced and archived in proprietary formats, open tools must be considered.)
- Demonstrator A demonstrator will be developed to illustrate applications defined in the scenario.
- Evaluation.
Standard evaluation methods will be used to focus on three aspects
of the project.
- the ability of the methodology to satisfying the requirements identified in task 1.
- the usability of the demonstrator by non-technical users: can it be used simply and effectively?
- the impact of such technologies on the authoring processes.
Related Work
Knowledge management and the wider issues relating to knowledge capture, modelling, publishing, reuse, maintenance, retrieval and extraction are being investigate by the Advanced Knowledge Technologies project, an Interdisciplinary Research Collaboration [AKTors 2000]. A potential enabling technology, the Semantic Web [Berners-Lee & Hendler, 2001] offers the possibility of structuring well-defined data, using computer recognisable metadata. In the Semantic Web, this knowledge is apparent from explicit statements about documents, however, it is necessary to make inferences from reading the contents of the documents. The effectiveness of agent technology in the fields of system integration and retrieval of information on the web technology has been well documented [El-Beltagy 1998].
A common theme in hypermedia design is the principle of separating the design issues to provide both physical and logical separation. The issue that no model has yet addressed is the narrative thread of an argument. When an 'expert' makes links in a linkbase, about a set of documents there is an underlying narrative thread being told. When these links are applied to other documents the links, although relevant to the document and topic under discussion, have lost the original thread. When the association (links) are originally made there is a coherence and synergy to them that is often lost when applied to another document, even when the context is the same.
Ontologies and hypermedia services have been combined to form a conceptual hypermedia system to enable documents to be linked via metadata describing their contents as an attempt to improve the linking of WWW documents at retrieval time (as readers browse the documents) and authoring time (as authors create the documents) [Carr et al, 2001]. Ontologies are also used to describe the interrelationships between concepts embedded in the documents to provide a new "catalogue of internal knowledge" [Bechhofer et al, 2001]. In addition, the use of ontologies is being investigated for use in scholarly publishing and discourse [Buckingham Shum et al, 2000]. This work on scholarly discourse, aims to expose the meaning hidden in research papers to allow the development of ideas to be tracked. This work by Buckingham Shum et al., provides a valuable insight into understanding the first of the 'cement' layers of figure 1. How this relates to macrostructure and the model as a whole, is still to be investigated.
Organisation's intranet sites are no longer restricted to the basic linking mechanisms of the early world-wide-web sites. Recent World-Wide-Web Consortium standards now promote a flexible hypermedia linking mechanism (XLink), which is compatible with the open hypermedia approach. In Open Hypermedia Systems (OHS), links are first class objects, which are stored and managed separately from multimedia data. This allows links to be stored, searched and sifted, and their use can be instrumented, as demonstrated by Michaelides et al. in providing a contextual open hypermedia link service [Michaelides et al. 2001]. Increasingly Web publishing applications are adopting the open hypermedia approach [Lowe & Hall 1998, Thistlethwaite 1997]. WebDAV and DeltaV are application-layer network protocols that provide capabilities for remote collaborative authoring, metadata management, version control, and configuration management [Whitehead 2001].
References
AKTors, Advance Knowledge Technologies, http://www.aktors.org,
Bechhofer S., Carr L., Goble C., Hall W., Conceptual Open Hypermedia = The Semantic Web? Position Paper. Proceedings of The Second International Workshop on the Semantic Web - SemWeb'2001
Carr, L., Bechhofer, S., Goble, G., Hall, W., De Roure, D. Conceptual Linking: Ontology-based Open Hypermedia Proceedings of The 10th International WWW Conference (in press) May 2001
Ceri S, Fraternali
P, Bongio A: Web
Modelling Language (WebML): a modelling language for
designing Web sites WWW9 Conference,
Christodoulou
SP, Styliaras GD, Papatheodorou. Evaluation of Hypermedia Application Development and management
Systems. Hypertext 98 The ninth ACM
Conference on Hypertext and Hypermedia, Pitt sburgh
El-Beltagy S. Approaches to
System Integration For Distributed Information Management.
Buckingham Shum S, Motta E, Domingue J. (2000) ScholOnto: An Ontology-Based Digital Library Server for Research Documents and Discourse International Journal on Digital Libraries 3 (3), 237-248
Fountain,
M. A., Hall W., Heath, I., and Davis H. C. (1990)
"MICROCOSM: An Open Model for Hypermedia with Dynamic Linking", in Proceedings
of Hypertext: Concepts, Systems, and Applications (ECHTÆ90), Rizk A., and Andre J. (eds.), pages 298-311, Cambridge
University Press
Garzotto F., Paolini P.Ā HDM- A Model-Based Approach to Hypertext Application Design.Ā ACM Transactions on Information Systems, Vol.Ā 11, No1 January 1993 p1-26.
Isakowitz T, Stohr EA., Balasubramanian P.Ā RMM: A design Methodology for Structured Hypermedia Design.Ā Communications of the ACM Vol.38 No8 August 1995 pp 34-44.
Berners-Lee T, Hendler J. The coming Internet
revolution will profoundly affect scientific information. Nature 410, 1023 - 1024 (
Lowe D,
Hall W, Hypermedia Engineering, the Web and Beyond,
Wiley 1999.
Lowe D and Webby R ōA Reference Model, and Modelling Guidelines for Hypermedia Development Processesö, The New Review of Hypermedia and Multimedia, Vol. 5, pp 133-150, 1999 Taylor Graham Publishers.
Michaelides DT, Millard DM,
Weal MJ, De Roure D. Auld
Leaky: A Conceptual Open Hypermedia Link Service. Open Hypermedia Workshop
OHWS7 in Hypertext 2001.
Schwabe D, Rossi G.Ā The Object-Orientated
Hypermedia Design Model.Ā Communications of the ACM August 1995,
Vol.Ā 38, No 8 pp25-46.
Shadbolt,
N.R., and Milton, N (1999) From Knowledge
Engineering to Knowledge Management British Journal of Management, 10,
309-322.
Thistlethwaite, P. Automatic Construction and Management of Large Open Webs, Information Processing and Management, 1997, 33(2), 161-173.
Whitehead, EJ Jr. WebDAV and DeltaV: Collaborative Authoring, Versioning, and Configuration Management for the Web. Hypertext 2001 Technical Briefing.
Track Record
The principal investigator of this project,
Dr Les Carr, and the co-investigator, Professor
Wendy Hall, are both members of the internationally renowned Intelligence, Agents, Multimedia Group
in the Department of Electronics and Computer Science at the
El-Beltagy, S., Hall, W., DeRoure, D. and Carr, L. (2001) Linking in Context Proceedings of HT01, the Twelvth ACM Conference on Hypertext, pp 151-160 (Winner of Best Paper Award)
Miles-Board, T., Kampa, S., Carr, L. and Hall W. (2001) Hypertext in the Semantic Web. Proceedings of HT01, the Twelfth ACM Conference on Hypertext, pp 237 - 238
Bechhofer, S., Carr, L., Goble, G., Hall, W. (2001) Conceptual Open Hypermedia = The Semantic Web? Proceedings of The Second International Workshop on the Semantic Web - SemWeb'2001
Carr, L., Bechhofer, S., Goble, G., Hall, W., De Roure, D. (2001) Conceptual Linking: Ontology-based Open Hypermedia Proceedings of The 10th International WWW Conference (in press)
De Roure, D., Walker, N. and Carr, L. (2000) Investigating Link Service Infrastructures. In Proceedings of Eleventh ACM Hypertext Conference. 67-76